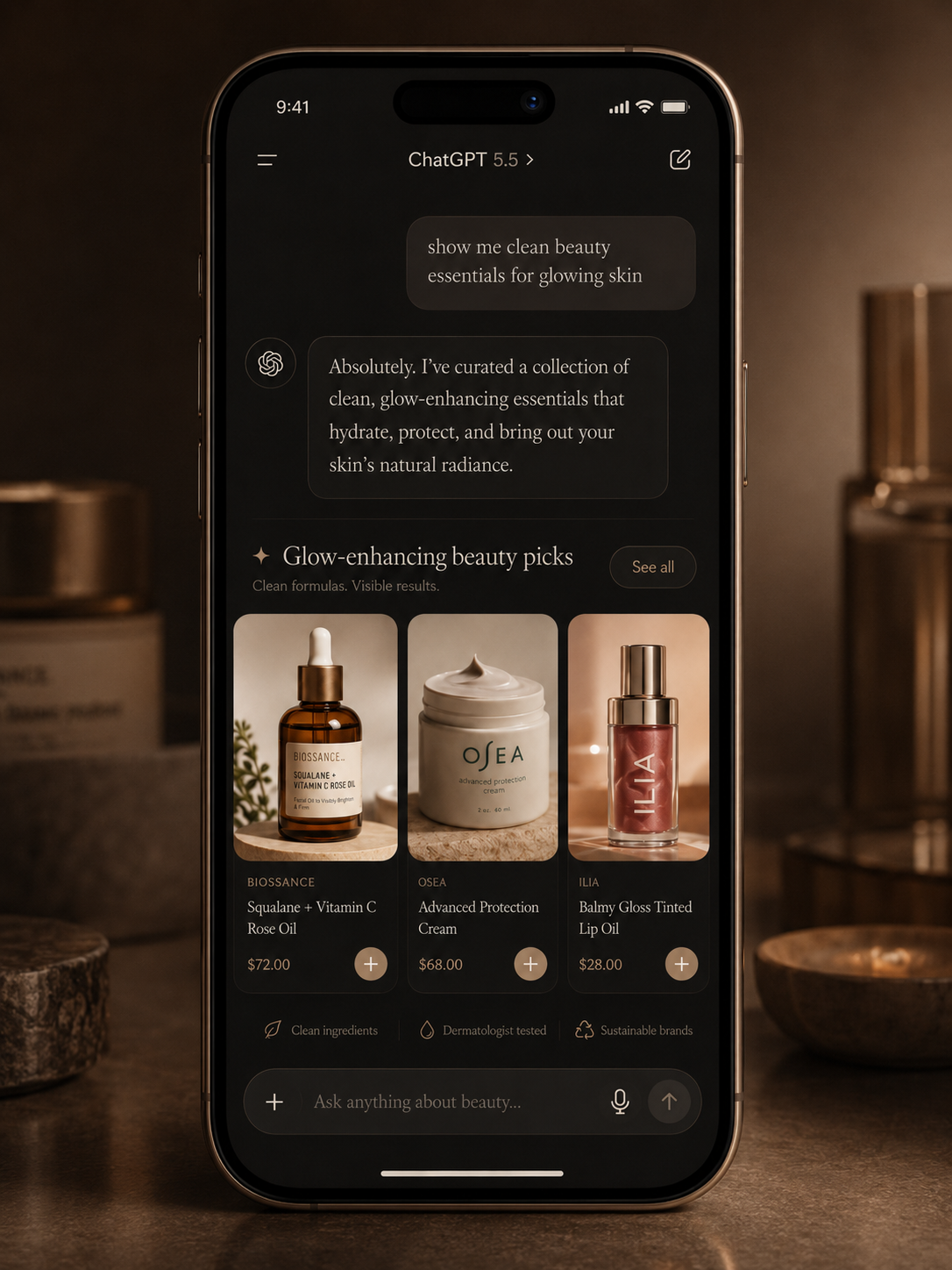
This is what ChatGPT, Gemini, and Claude do every time someone asks them for product recommendations.
Drag the agent. Watch it from every angle. Then run your own audit.
Watch an AI agent see your store.
We monitor the same 6 AI shopping agents that decide which products get recommended to shoppers. Drag the agent →
Multi-agent: ChatGPT · Gemini · Claude · Mistral · DeepSeek
Your competitors are being recommended by AI agents. You're not even in the conversation.
Shopify already ships your catalog to ChatGPT, Claude, Gemini, Mistral and DeepSeek.
They decide — on behalf of the shopper — which brand gets the placement. First-movers compound. Late-movers pay 3–4× to catch up.
AI TRAFFIC GROWTH
+700%
AI traffic to Shopify stores, trailing 12 months.
Source: Shopify Merchant Insights, Q1 2026
+700%YoY growth
Q1 '25Q1 '26
CATALOG VISIBILITY GAP
41%
of Shopify products are invisible to at least one major AI shopping agent.
Benchmarked across 364 public Shopify catalogs · 10 verticals
41%
59% indexed
● Invisible to agents● Indexed
OPEN DATASET
153k+
Ground-truth captures across 6 AI shopping agents in our open dataset.
Updated 2× daily · github.com/commerce-agentic
+2,400 captures /day · CC0 dataset
ChatGPT just recommended three brands.
Yours could've been one of them.
AI agents read every Shopify catalog and pick the ones their answer pages will feature. Brands with clean signals win the placement. Catalogs that read like noise get skipped.
Real query · captured on ChatGPT
LIVE EXAMPLES FROM OUR OPEN DATASETReal captures from our public CC0 pipeline · 228k+ in dataset · 6 agents tracked daily
2m agoGemini recommended "sustainable sneakers" — a smaller brand won the click
12m agoClaude summarized "waterproof boots under $200" — competitor took the placement
17m agoPerplexity answered "premium fitness apparel" — top 5 picks were your competitors
First-mover advantage
AI rankings compound. Brands that optimize first tend to hold their position.
Once a brand earns a mention rate in ChatGPT for "best [category]", agents reinforce that recommendation in subsequent responses. It's easier to defend a position than to displace one. Optimizing your catalog now is the cheapest move you'll make this year.
AI Catalog Score finds what's holding your products back, fixes it for AI discovery, and proves the lift — so you win more sales.
1
SCANAudit every product
✓
+24 more
Skincare$48
VERDE BOTANICAL RENEWAL SERUM
Issues4
Updated2min
AI Readiness Scoreⓘ
63/100
8 AI-readiness signals
✓Title clarity9
✓Description7
✕Alt text4
!JSON-LD5
✓Category8
!Metafields6
✓Reviews7
✓Pricing8
Top issues
Missing alt text423
Thin descriptions312
Missing JSON-LD287
Incomplete ingredients / metafields156
Live scan
2sScanning VERDE Serum · 8/8 signals
4s+12 pts potential from JSON-LD
6sQueueing alt-text fix · 423 SKUs
→2
FIXAuto-fix with preview
AI Readiness Score
36
79
↑+43 pts
BEFORE
Botanical Serum
Hydrating serum for the skin. Helps improve skin look.
Description9 words
✕No alt text
✕Thin description
✕Missing ingredients
→
AFTER (PREVIEW)
Botanical Renewal Serum — Barrier Repair for Sensitive Skin
A lightweight, plant-powered serum with centella, squalane & niacinamide to strengthen the skin barrier, calm redness and hydrate deeply. For sensitive, dry & combination skin.
Description42 words
✓Alt text added
✓Rich description
✓JSON-LD added
✓Ingredients & skin type optimized
→3
PROVEMeasure causal uplift
Causal uplift (Optimized vs. Control)p < 0.05
+27.3%
ATTRIBUTABLE REVENUE LIFT
95% confidence
Optimized itemsControl groupApr 15 Apr 22 Apr 29 May 6 May 13 May 20 May 31
Lift is real🛡p < 0.05Statistically significant
Incremental revenue$18,642Last 30 days · +12% w/w
Test windowMay 1–3130 days · ongoing
Products tested143Auto-selected · DiD
Treat 72Ctrl 71
Stop losing sales to invisible products.
Install in 90 seconds. First scan in under 4 minutes. Free plan, no credit card.
FREE PLAN · NO CREDIT CARD · SHOPIFY PARTNER CERTIFIED
Live · last 60 min
$3,420
redirected to competitors across unoptimized Shopify stores in our dataset
≈ $5.1k / hour904 catalogs scanned
03 HOW WE BUILT THIS
Six pillars behind the score.
The hard moats - in plain English, no jargon.
Multi-agent
5 AI agents. Captured at the same moment.
ChatGPT, Claude, Gemini, Mistral, DeepSeek - queried synchronously, 2,400 times a day. Perplexity joins Q3. Every other tool captures one agent at a time, hours apart, then compares results that aren't comparable. You can't optimize for what you can't see - fairly.
Q3
Causal proof
Every fix proves it worked. With math.
We split your catalog into control and treatment, measure the actual revenue lift, and only call it a win if p < 0.05. Real A/B, not vibes.
Control+0%
Treatment+9.2%
Performance pricing
Pay nothing if we don't lift your revenue.
5% of the AI-attributed uplift, capped at $5k/month. If your AI sessions don't grow, you owe nothing. The only Shopify app on a true success fee.
Other apps
$49–499/mo
AI Catalog Score
5% of lift
Open standard
Our work is open. Lock-in is impossible.
The scoring methodology is public domain. The agent skills are open source. Anyone (including Shopify) can adopt the spec tomorrow. You're not betting on a black box.
⊕CC0 1.0 · Spec⊕MIT · Skills
Score Guarantee
+10 points in 30 days, or your money back.
The only Shopify AI app that puts the guarantee in the Terms of Service, not the marketing copy. If your AI Catalog Score doesn't lift by at least +10 points within 30 days of activation, every dollar comes back. No fine print.
+10
PTS · 30 D
Written in ToS v1.0
Full refund, no questions
Network effect
Every merchant makes the score smarter.
Every catalog scan sharpens our per-vertical baselines (10 verticals modeled). Every A/B run feeds the Shared Experiment Library. The product gets better the more merchants we have. Static rule-based scoring tools don't.
Captures
228k+
Verticals
10
04 PRICING
Plans for every Shopify catalog.
Free plan up to 50 SKUs · cancel any time · Score Guarantee on every paid tier.
Everything merchants need to know before installing. Can't find your answer? Ask us directly.
90 seconds. Install from the Shopify App Store, grant Admin API scopes, and the first scan kicks off automatically. Your full catalog is scored in under 4 minutes for a 500-SKU store, ~12 minutes for 5,000 SKUs. No developer involvement, no theme code edits, no Liquid required.
SEO tools (Yoast, Ahrefs, SurferSEO) measure how Google's search crawler ranks pages. We measure what AI shopping agents (ChatGPT, Claude, Gemini, Mistral, DeepSeek - Perplexity joining Q3) actually recommend when our standardized buyer-intent query suite is issued daily. The two systems share some signals (structured data, alt text) but weight them very differently. SEO tools also can't tell you which products are missing from agent answers - we can. Note: our captures are a benchmark, not a sample of real shopper traffic (which is private to each agent).
Three structural differences: (1) we capture 5 AI agents synchronously on the same query (Perplexity coming Q3) - Profound watches 2-3, Athena AI watches ChatGPT only, ShopRank uses 4 dimensions vs our 8; (2) we prove fixes worked causally with DiD + Welch's t-test (p < 0.05) - they use observational attribution; (3) we offer a money-back Score Guarantee - none of them do. Pricing comparison: 40rty $49-499/mo fixed · ShopRank $9.99/100 SKUs · SKAW $19.99/mo · AI Catalog Score $49-399 with Performance tier at 5% of uplift (zero if no lift). Plus our scoring methodology is CC0 open source; theirs is closed.
No measurable impact on storefront speed. We use the Shopify Admin API server-side (off-thread, no shopper-facing JS). The only thing that touches your theme is an optional JSON-LD injection in product page headers - that adds ~2 KB to the HTML (smaller than a typical logo image). Tested against Core Web Vitals on 50+ stores: no LCP/FID/CLS regression.
Run the free 60-second scan first. If your score is already A+ (90 or above) across all 8 dimensions and 5 agents, you genuinely don't need us - we'll tell you that and suggest audit-only tier ($0). In practice, the average self-reported "optimized" catalog scores B- to C+ on first scan. Agentic commerce signals (JSON-LD product schema, metafield completeness, multi-agent reviews) are different enough from classic SEO that very few merchants are actually optimized for both.
Opposite effect. JSON-LD structured data, alt text, richer product metadata, and consistent metafields are universally good for search engines. Google indexes the same signals AI agents use - they just weight them differently. Beta merchants observed +3-8% in organic Google traffic in the 30 days following catalog optimization, alongside the AI lift.
We measure your AI-attributed revenue (sessions and orders coming from ChatGPT, Claude, Gemini, Mistral, DeepSeek - identified via referrer signals + User-Agent patterns + UTM matching) over a 30-day baseline before activation, then monthly after. The 5% only applies to the uplift over baseline, capped at $5,000/month. If sessions don't grow, your bill is $0. The causal model and attribution logic is documented in our open spec - you can verify our math.
AI agent attribution is harder than classic web analytics because referrers are inconsistent. We use a 3-signal stack: (1) ?utm_source=chatgpt-style explicit UTMs when agents pass them; (2) User-Agent matching for known agent crawlers (OAI-SearchBot, PerplexityBot, ClaudeBot, Google-Extended, Mistral-AI, DeepSeek-Crawler); (3) temporal correlation with our ground-truth captures - when our pipeline records a recommendation of your product at time T and your store gets a session referrer-less or with a generic referrer within ±10 minutes, we attribute it.
Honest about limits: we capture roughly 60-80% of AI-attributed traffic. Some agent outputs don't leave a trail at all (voice, screenshot, copy-paste). We err conservative, so our 5% performance fee is calculated on what we can prove - never inflated. The full methodology is in the CC0 spec.
Fair question. Yes, you can read our CC0 spec, fork our MIT skills, and self-audit your catalog manually. That's the point - we don't want to hostage you. What you pay for is tooling, automation, and proof:
(1) Multi-agent synchronous capture - querying all 5 agents at the same moment, 2,400 times a day, on the same query. Trivial to describe, ~80-120h of infra to build (rate-limits, retries, billing, agent API differences). (2) The dataset itself - 79k+ captures grow by 2,400/day, you can read it but you can't recreate it without our pipeline running for months. (3) The causal A/B framework - DiD + Welch's t-test on session deltas, control split, p-value reporting. Doable but ~40h of stats work. (4) Apply-into-Shopify - reading the spec is easy, but writing automated fixes with dry_run guardrails, audit journaling, 30-day undo, GDPR compliance is real product work. (5) Score Guarantee - we put +10 pts/30 days in the ToS. No one self-auditing has a refund mechanism on themselves.
Plenty of merchants will read the spec and self-fix. We're betting most prefer to pay the tooling fee and skip the build.
The free plan lets you audit up to 50 SKUs with the full scoring engine, including the AI Readiness Score, Agentic Checklist, and AI Query Simulator (3 queries/day). No credit card required, no expiry, no feature throttling on the 50 SKUs you choose. When you outgrow it, upgrade to Growth ($49/mo, 500 SKUs), Pro ($149/mo, 3,000 SKUs), or Performance ($399/mo, unlimited SKUs) directly from the Shopify admin.
Today the published price is the price: $49 / $149 / $399 per month, or 30% off when billed yearly. We don't run hidden-trial games, surprise upsells, or a price-creep schedule baked into the terms. If we ever change list pricing, existing subscribers stay on their current rate for the duration of any active billing period and get clear notice before any renewal at a new price.
If your AI Catalog Score doesn't lift by at least +10 points within 30 days of activating a paid plan (and you applied at least the top 5 recommended fixes), every dollar you paid in that window is refunded. No support ticket required - we auto-refund when the threshold isn't met. The guarantee is in the Terms of Service v1.0, not the marketing copy.
No. Every mutation runs with dry_run: true by default. We preview the exact change, you click approve, then we apply. Every action is journaled per-SKU with a 30-day full undo. We never overwrite product titles or descriptions without explicit consent, never touch pricing or inventory, and never modify any field you've marked as locked.
Causal A/B testing using Difference-in-Differences with Welch's t-test on per-product session deltas. We split your products 50/50 treatment/control, measure AI-attributed sessions before and after the fix, and only declare uplift when p < 0.05. Every other tool gives you observational attribution ("correlation"). We give you statistical proof ("causation"). Full methodology in the CC0 spec.
Read access: products (titles, descriptions, images, metafields, variants), order metadata (for AI traffic attribution - no customer PII), and theme files (for optional JSON-LD injection). Write access: only the fields you explicitly approve in the dry-run preview. We never store customer names, emails, phone numbers, or addresses. Full privacy policy at privacy.html.
Yes - the 8-dimension scoring spec is published under CC0 1.0 (public domain) at commerce-agentic/agentic-commerce-spec. The reference TypeScript implementation, scoring weights, and ML uplift models are MIT. You can fork it, audit it, build a competing product, or wait for Shopify/BigCommerce/WooCommerce to adopt it in their official docs. We make money on the tooling, automation, and proof - not the score itself.
Yes. On uninstall, all data is purged from our database within 48 hours per Shopify's GDPR webhook requirements (we honor app/uninstalled, shop/redact, and customers/redact). Score metafields written to your products stay there (you own them on your Shopify), but you can delete them manually via the admin or with one API call - we provide the script in our docs.
Ready to ship AI-ready catalogs?
Get scored against the same 5 AI agents that already shape catalog visibility - ChatGPT, Claude, Gemini, Mistral, DeepSeek (+ Perplexity coming Q3). Install in 90 seconds.